O Recebe NFSe é uma solução projetada para lidar também com documentos fiscais que não estão no formato XML, padrão comum adotado pelo fisco brasileiro.
A aplicação utiliza tecnologia de Reconhecimento Óptico de Caracteres (OCR) para identificar o texto dos documentos em outros formatos, como PDF ou JPG. Depois, através de modelos de Inteligência Artificial (IA) treinados, realiza a extração dos dados e disponibiliza-os em formato XML.
Neste artigo, você encontra informações sobre as etapas de processamento de documentos, além de especificações técnicas sobre o fluxo de leitura, tratamento de imagens e páginas, e análise de campos obrigatórios e livres.
Leia o artigo Introdução ao Recebe NFSe para ficar por dentro do funcionamento padrão da solução de recebimento de NFSe da Oobj.
Treinamento da IA
O treinamento do modelo de IA é um processo iterativo que envolve a coleta de amostras dos documentos (mínimo de 30 do mesmo município), a preparação dos dados, a escolha da arquitetura do modelo, o treinamento, a avaliação e o ajuste fino. Por meio dos dados processados pela tecnologia, a ferramenta vai aprendendo e aperfeiçoando a leitura automatizada.
Fluxo de leitura e extração de dados
Cada documento recebido pela aplicação passa pelas seguintes etapas:
- Classificação do tipo de documento;
- Verificação e tratamento da resolução da imagem;
- Ajuste de cores e tonalidades;
- Tratamento de background (remoção de ruídos no entorno);
- Ajuste de posicionamento (ângulo e perspectiva);
- Identificação dos cantos do documento (corner);
- Identificação de marcas d’água;
- Ajuste Denoising (ruídos sobrepostos);
- Análise de múltiplas páginas;
- Análise de campos obrigatórios;
- Análise de campos livres.
Ao fim do processo, o Recebe NFSe entrega um arquivo XML em diretório definido durante a implantação.
PDF com múltiplas páginas
A aplicação processa PDFs com várias páginas de duas formas:
- Múltiplas páginas de um mesmo documento: se um documento PDF contém várias páginas (como uma fatura de energia e outros), a solução converte todas as páginas em um único XML; e
- Múltiplas páginas de diferentes tipos de documentos: a aplicação identifica automaticamente quebras de página que separam diferentes documentos, processa as informações de cada um e gera um arquivo XML individual para cada documento detectado. Por exemplo, ao receber um arquivo PDF de 10 páginas com 10 documentos diferentes, a aplicação processa e devolve 10 arquivos XMLs separados.
Campos obrigatórios
Após o tratamento de imagem para melhorar o processo de extração de dados, a solução aplica regras para verificar se todos os campos obrigatórios estão preenchidos.
Esses campos incluem informações essenciais para garantir a verificação correta das retenções tributárias no documento fiscal de serviços. Confira a seguir os campos obrigatórios analisados pela solução:
- Código de Verificação
- Data de Emissão
- CNPJ Prestador
- Valor da Nota
- CNPJ Tomador
- Número da Nota
- Razão social Prestador / Tomador
- Código do Serviço
Revisão manual
Se durante a leitura e extração dos dados for identificada alguma divergência, como a ausência de informações em campos obrigatórios, o documento será enviado para uma fila de revisão manual antes de seguir o fluxo, onde será revisado por um analista humano em até 48 horas úteis.
Campos livres
Os documentos fiscais possuem campos de texto livre, permitindo que o contribuinte faça observações sobre a transação registrada. Com o Recebe NFSe, é possível extrair informações desses campos e usá-las para otimizar sua rotina fiscal.
Se o campo livre Descrição do Serviço for preenchido obedecendo um padrão para o número do pedido de compra ou número da folha de serviço, o Recebe NFSe poderá ler e converter esses dados para um campo estruturado. Assim, esse campo livre se torna obrigatório para o fluxo de leitura e estratificação de dados.

Dessa forma, a integração entre a nota tomada e o número cadastrado no seu sistema ocorre automaticamente, sem que um usuário precise inserir essas informações.
O padrão do número (como ‘PEDIDO: 0000000000’ ou ‘FOLHA DE SERVIÇO: 0000000000) é único e definido durante a implantação da solução.
Cancelamento de NFSe
A NFSe não possui evento de cancelamento e, por isso, o cancelamento é feito por meio de marcas d’água no documento enviado em PDF ou imagem JPG. Quando o Recebe NFSe identifica uma marca d’água de cancelamento, o status do documento aparecerá como “Cancelado” no Monitor Oobj.
Exemplo de NFSe com a tarja de Cancelamento:
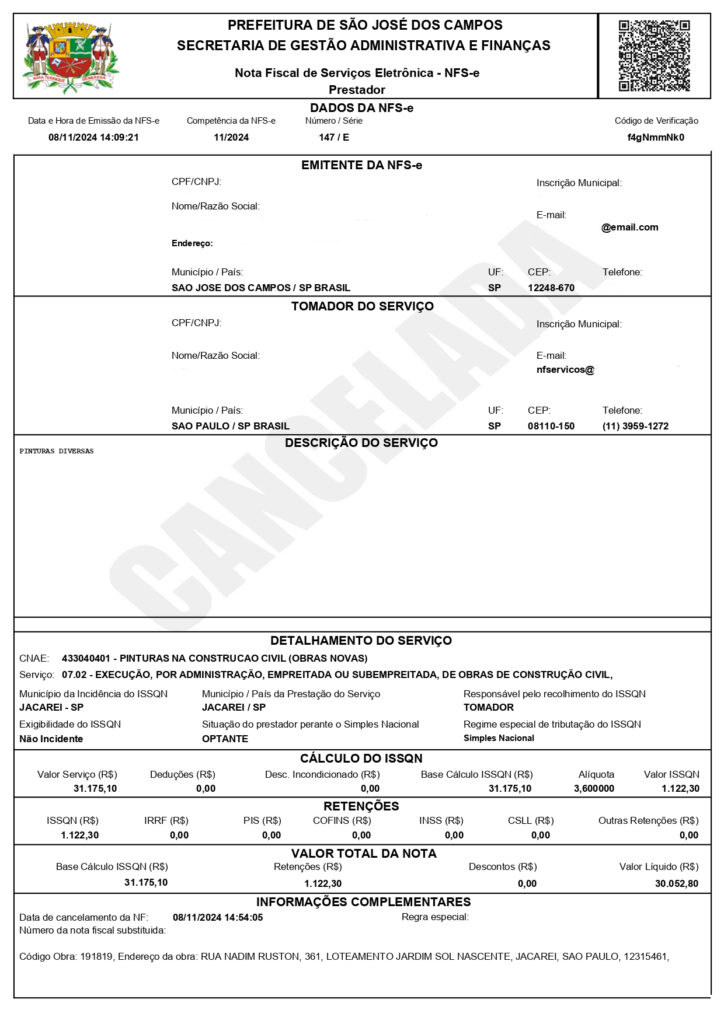
Se a aplicação está configurada apenas com o recebimento via e-mail, é necessário que o prestador reenvie a nota (PDF) com a marca d’água que indica o cancelamento. Dessa forma, o documento é reprocessado e o status é alterado no Monitor Oobj. Caso contrário, o status não será atualizado.